




TL;DR
Analyzing interview data in qualitative research is the step where most research programs stall. Qualitative interviews produce non-numerical data that is rich but hard to synthesize at scale, and manual coding and thematic analysis don't scale with study volume or team size.
A repeatable framework matters: move from raw data to coded themes to cross-participant patterns before synthesis
AI-assisted analysis raises credibility when it preserves source traceability, and introduces risk when outputs cannot be traced back to original participant responses
Video recordings and other nonverbal signals are lost when teams rely on interview transcripts alone; multimodal analysis captures what text misses
The output standard has changed: stakeholders expect findings backed by evidence, not summaries
Knowing how to analyze interview data in qualitative research is, for most enterprise teams, less a methodology question and more a logistics crisis. Qualitative researchers arrive at the synthesis stage with hundreds of pages of interview transcripts, no repeatable system for spotting patterns across study participants, and a clock that has been running since the first interview was scheduled. The qualitative data is rich. The process for making sense of it at scale is not.
The operational consequence is predictable: by the time manual analysis finishes, the business decision has often already been made. A product roadmap gets locked. A campaign goes to production. A packaging concept advances to testing. The key insights arrive in time to inform the next research project, not the one that mattered.
One important framing before we begin: the bottlenecks described here are workflow constraints, not limitations inherent to qualitative research itself. The method is more capable than the old research process allowed. What is changing now is the infrastructure around it.
Why Interview Analysis Becomes a Bottleneck
Manual coding is where qualitative research timelines collapse. Many qualitative researchers finish 20 in-depth interviews and face 300 or more pages of interview transcripts. Tagging themes by hand, cross-referencing participant responses, and resolving disagreements when two team members code the same passage differently: that process routinely takes two to three weeks before a single finding reaches a stakeholder.
The scaling problem is structural. When market research and consumer insights teams aim to conduct qualitative research at any meaningful volume, the process becomes time-consuming in ways unrelated to the quality of the qualitative data collected. Transcript review time grows in direct proportion to the number of sessions. The only lever most teams have is adding headcount, which is rarely available, or narrowing the sample, which compromises the qualitative study.
The result is that most enterprise teams run qualitative research studies far less frequently than their stakeholders need. Each research project becomes a discrete event: scoped, commissioned, delivered, and archived. Findings live in PowerPoint decks or PDF reports that no one can search. When a brand team asks a question six months later that overlaps with a prior study, the insights team often has no practical way to surface the relevant data from existing data sources. The study is rerun at full cost and full timeline because the previous work is effectively invisible.
Agency dependency compounds this. Teams that need to continuously gather customer feedback cannot rely on external moderators and analysts. Each study requires briefing the agency, aligning on the guide, waiting for fieldwork, and then waiting again for the debrief. That cycle works for a quarterly brand tracker. It does not work for a product team making decisions on a two-week sprint cadence, or a marketing team validating a campaign concept before the media buy closes.
What research operations and insights teams need is not faster manual analysis. They need a framework that changes the unit of work: one where synthesis happens as data arrives, outputs are traceable to source, and findings compound across studies rather than expiring in a deck.
The traditional interview analysis workflow (and where it breaks down)
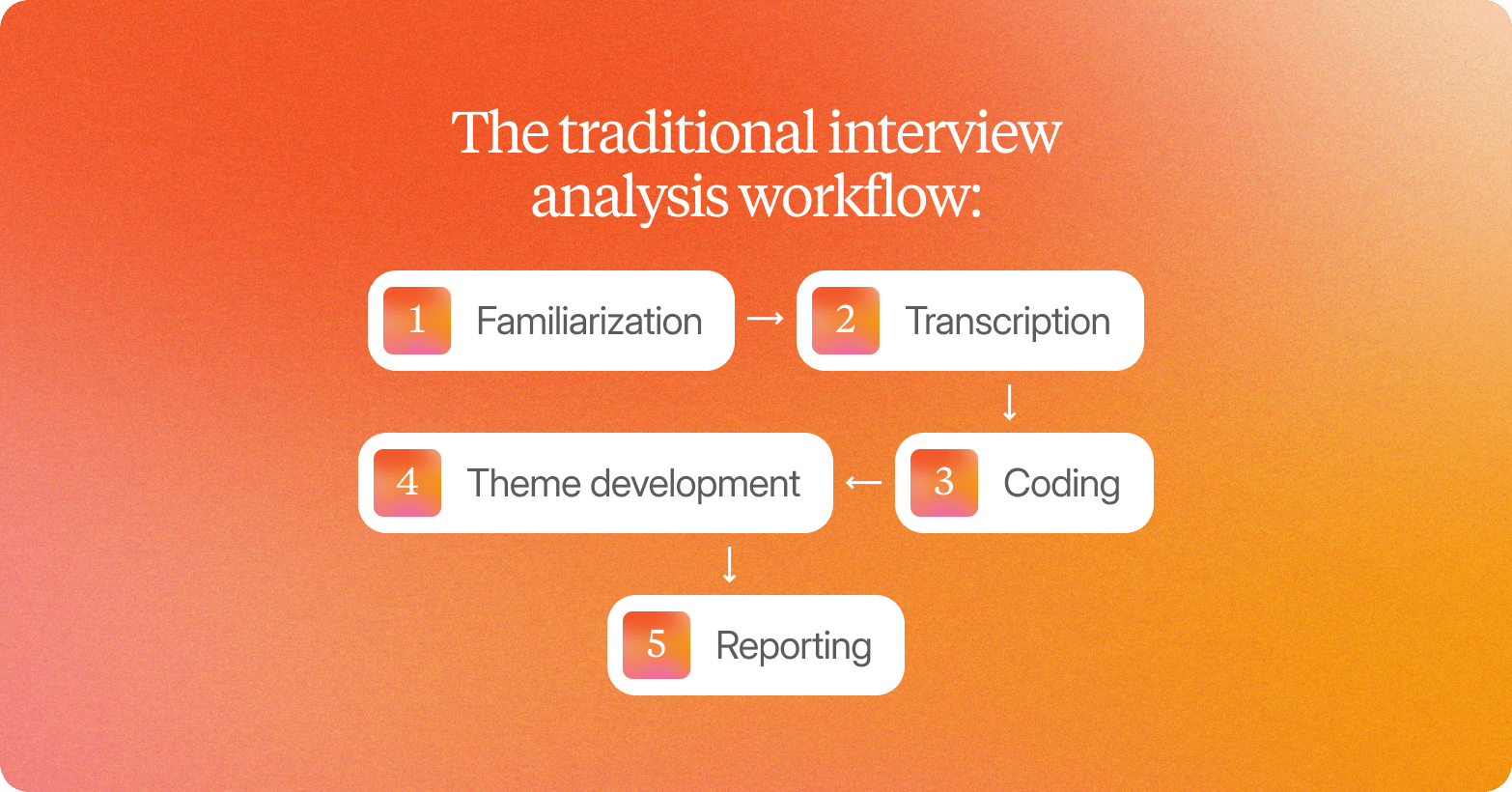
The traditional qualitative research design follows a well-established sequence: familiarization, transcription, coding, theme development, and reporting. This research process applies across qualitative research methods, from in-depth interviews to focus groups and group discussions. Each step has genuine methodological value. Each step also carries a hidden operational cost that compounds as research volume grows.
Familiarization
Is where analysts listen back through recordings, take free-form notes, and build an initial sense of what participants said. When a qualitative study involves six or eight qualitative interviews, this works. When it involves 40 or 80, many researchers report spending days in this phase alone, with no structured way to capture first impressions or flag moments worth returning to. Important signals, a hesitation before answering, or an unprompted brand mention, get noted informally or not at all.
Transcription
Converts recordings into textual data. Generic transcription services often lack speaker identification and timestamp precision, so analysts spend additional time manually linking interview transcripts to the correct participant and moment in the recording. That linkage matters when a stakeholder asks which participant said something, or when a finding needs to be verified against the original conversation.
Coding
Is where knowing how to analyze qualitative interview data at scale reveals its true complexity. Coding qualitative data manually in Word documents, Google Docs, or spreadsheets is manageable for a single analyst working on a contained dataset. It becomes fragile the moment a second analyst touches the same interview transcripts. Without version control, codebooks drift. One analyst tags a concept as "price concern," another as "value perception," and the two never reconcile. By the time the study reaches reporting, the coding layer is inconsistent in ways that are difficult to detect and harder to defend.
Theme development
Is an iterative process: moving between codes, collapsing some, splitting others, and checking that each theme is grounded in the data. Common themes emerge gradually, and as the number of interviews increases, the cognitive load scales faster than the time available.
Reporting
Is where accumulated friction becomes visible to stakeholders. Analysts extract representative quotes, package findings into slide decks, and present conclusions that stakeholders cannot independently verify. The connection between a theme on a slide and the conversation that generated it is invisible, and many stakeholders won't act on findings they cannot trace.
This workflow was designed for a world where qualitative research was periodic, small-scale, and agency-led. It breaks down when teams need continuous customer understanding: monthly concept tests, rolling brand tracking, rapid-cycle product discovery. At that pace and volume, the manual steps don't compress. They accumulate, and the credibility gap widens.
7-step guide for analyzing interview data

Step 1: Prepare your data for analysis
Raw data from interviews and field recordings is not analysis-ready. Before coding or cross-interview comparison can begin, every session needs a consistent format: speaker labels, timestamps, and a header capturing the participant code, date, and market or language. Organizing transcript files with consistent naming is what makes qualitative data collection tractable at scale. It lets researchers spot themes, pull comparable quotes, and navigate to relevant moments without re-reading from the start. In multi-market studies, manual transcription and translation can consume days before analysis begins. Establish a file naming convention: [ParticipantID][YYYY-MM-DD][Market-Language], for example, P012_2025-09-14_DE-German.
Step 2: Familiarize yourself with the dataset
Before touching a codebook, engage with the raw data and aim to gain insight before any structure is imposed. Pull a sample of eight to twelve sessions and explore without preconceived notions about what the data contains. Write memos to capture initial observations before formal coding begins. You are not coding yet. You are listening for patterns that a framework built before fieldwork would never anticipate. This step is especially valuable in exploratory research, where the research topic is still being defined. This is also where video recordings earn their advantage over interview transcripts. A participant who says "I think the price is fine" while visibly hesitating tells a different story than the words alone suggest. Teams that skip familiarization tend to find only what they expected.
Step 3: Develop a coding framework
Qualitative coding requires a shared framework before analysis begins. Without a codebook, two analysts working through the same set of interviews will apply the same label to different aspects of the data, producing qualitative analysis that cannot be aggregated or defended. Three approaches exist: deductive coding starts from research questions and applies predetermined codes; inductive coding, closer to grounded theory, lets codes emerge from what participants actually say; and structural coding organizes data by research objectives and research topic. Most enterprise research studies benefit from a hybrid. Whichever coding method you use, decide upfront whether to build on existing codes from prior studies or remain open to new codes emerging. Including thematic, narrative, or content analysis as parallel lenses can provide a more complete picture. Every code needs a precisely written definition. "Price sensitivity," for example, should distinguish budget constraints from perceived value concerns, not flag every mention of cost. That level of specificity is what makes findings credible when a CMI director presents them to a leadership team.
Step 4: Code the interviews
Tag each meaningful excerpt with a code that reflects the underlying concept it represents. A participant describing a product as "confusing to navigate" and another calling it "hard to figure out" belong under the same code. Grouping at the coding stage is what makes pattern recognition possible in the data analysis phase that follows. On a first coding pass, focus on applying codes consistently across analysts before refining. Manual tagging in Word or Excel becomes unmanageable past 15 to 20 interviews; systematic coding at that scale requires either dedicated qualitative data analysis software or an end-to-end platform. Conveo's AI analysis handles the initial pass, surfacing recurring patterns across qualitative data collected across all sessions before an analyst has opened a single document. The human role remains essential: validating themes, removing false positives, and confirming alignment with research questions.
Step 5: Identify themes and patterns
Codes are the raw material. Key themes are the answers to your research questions. Group related codes into higher-level themes by looking for the shared concern or tension that connects them. Find insights that hold across eight or ten participants before elevating a pattern to a finding. Draft each theme, then return to the full data set to test whether the evidence supports it across different participant perspectives. Common themes often emerge from the most frequent codes, but important insights can surface in minority patterns. Every theme should link to specific verbatim quotes and, where video interviews were conducted, to the corresponding clip. Traceability is what separates a defensible finding from an assertion.
Step 6: Validate and refine findings
Most themes survive the coding stage intact. Now comes the step that separates credible findings from convenient ones: actively looking for study participants who contradict the dominant pattern. This is a negative case analysis. Return to your analyzed data and ask who did not fit the emerging theme. A participant who expressed indifference, where others showed enthusiasm, provides a broader perspective that is often the most valuable signal in the data set. Negative cases help researchers draw conclusions with appropriate precision. Presenting a finding as "most participants expressed X, while a distinct subset experienced Y" is more defensible than presenting X as universal. Once themes are stress-tested, a searchable insight library that connects findings across multiple sources and research projects reduces repetitive work and helps patterns compound over time.
Step 7: Package findings for stakeholders
Research findings die in decks. The packaging step is where that pattern breaks or repeats. Producing findings that decision-makers can act on requires outputs at two levels: a full thematic analysis for practitioners who need to interrogate the evidence, and a sharp executive summary for decision-makers who need to act quickly. Lead the executive summary with the business implication, not the methodology. "Participants expressed confusion around pricing" is a research observation. "Price architecture is creating a conversion barrier for the 35 to 50 segment" is a business implication that gets acted on. Where video interviews were conducted, shareable clips convey key insights across teams in ways that text-only reports cannot. Every theme should trace back to the video timestamp and verbatim quote that generated it.
AI-Assisted interview analysis: What changes (and what doesn't)
AI does not replace the analyst in qualitative research. It changes where analysts spend their time. Pattern recognition across dozens or hundreds of interview transcripts, which once took days of manual coding, now takes minutes. What remains unchanged: the judgment calls that determine whether a pattern is meaningful, whether a theme reflects genuine consumer behavior, or whether a finding actually answers the business question.
In practice, AI analysis of qualitative interview data works like this: AI-surfaced theme clustering surfaces candidate patterns across all sessions simultaneously, flagging recurring language, sentiment shifts, and behavioral signals. Analysts then review those clusters, collapse or split themes based on context, and tie final findings to specific video clips and verbatim quotes. That last step is not optional for enterprise delivery. Stakeholders who cannot trace a finding back to a real participant conversation will not act on it.
Discover how to build and launch a study in Conveo →
Point tools covering only transcription or only analysis still require separate systems for recruiting, interviewing, and packaging evidence. Every handoff creates friction, introduces version control risk, and slows delivery.
General LLM synthesis can surface themes quickly, but it fails the governance test. Outputs are not reliably traceable to specific interview evidence, making them difficult to defend in stakeholder reviews and impossible to meet enterprise compliance requirements.
Purpose-built end-to-end platforms connect interviewing, analysis, and reporting on the same platform in a single traceable system. Conveo's product is built on this model: every AI-generated theme links back to the original video moment that produced it, every finding is anchored to a real participant conversation, and the full workflow runs inside a SOC 2 certified, GDPR-compliant environment with optional EU data hosting. For enterprise procurement teams, that compliance infrastructure is a procurement requirement, not a footnote.
What AI cannot do is equally important to note: interpret cultural nuances that change the meaning of a response, assess whether a theme is strategically significant, or decide which findings matter most to the business question. Those judgments belong to the researcher.
Beyond transcripts: Multimodal analysis and multi-Market research
Analyzing video, tone, and nonverbal signals
When teams analyze interview data in qualitative research using only interview transcripts, a significant layer of meaning disappears before analysis even begins. Participants communicate through more than words. Their attitudes and behaviors toward a concept show up in tone before they finish describing it. The hesitation before answering a pricing question, the slight frown when a new product is introduced, the visible uncertainty in their voice when they describe a brand: none of that survives the journey from video to text.
Consider two participants who both say "I like it" when shown a new packaging concept. In text, those responses look identical. In video recordings, one participant leans forward, voice rising with genuine interest; the other delivers the same words in a flat, polite tone, eyes already moving away from the stimulus. Transcript-only analysis codes both as positive. Multimodal qualitative analysis distinguishes them and develops a deeper understanding of what participants actually mean.
Platforms that capture multimodal signals alongside interview transcripts, including Conveo, read across three layers during every session: voice tone, which surfaces confidence versus uncertainty and hesitation patterns; facial expressions, which register confusion, delight, and skepticism; and on-screen objects, including product packaging, competitor products, or elements of the participant's natural environment. When findings are tied to timestamped video clips, stakeholders can see the reaction rather than read a summary of it. That traceability changes the dynamic in a briefing room.
Multi-market research: Translation, coding, and cross-cultural consistency
Analyzing qualitative interview data across multiple markets is one of the more demanding problems in enterprise research operations. When a qualitative research study spans five countries and four languages, transcription goes to one vendor, translation to another, and coding is done manually by analysts who may not share a common codebook. The result is slow, expensive, and structurally inconsistent.
The consistency challenge runs deeper than most teams expect. Codes and themes must be culturally equivalent across markets, not just accurate translations. Consider "value for money." In a price-sensitive market, participants use it to describe functional affordability. In a premium market, the same phrase signals reassurance that quality warrants the price. A keyword-matching approach codes both identically. An analyst working with cultural context codes them as meaningfully different signals. That distinction can change how a product is positioned or launched in each market.
Platforms with 20+ language support reduce this burden significantly. Conveo's CX team workflows support 20+ languages, hold SOC 2 certification, and provide EU data hosting, meeting the compliance baseline that enterprise procurement teams require before any multi-market research program can be approved.
4 common mistakes that undermine interview analysis quality

Knowing how to analyze qualitative interview data correctly is as important as conducting the interviews themselves. The four mistakes below are where the quality of analysis most often breaks down in qualitative research studies.
Poorly designed interview guides
A weak interview guide, built around a static list of research questions, produces surface-level answers that resist meaningful coding. When every participant follows the same rigid script, the qualitative data collected becomes shallow and repetitive. Adaptive probing, where follow-up questions respond to what a participant actually says, generates the richer responses that thematic analysis requires. Conveo builds adaptive probing into the AI interviewer layer, so the depth needed for credible analysis is captured before a single transcript is coded.
Coding without a framework
Tagging concepts ad hoc leads to inconsistent codes that cannot be compared across participants. The result: a codebook shaped by who did the coding, not what the data contains. A predefined codebook ensures that two analysts produce consistent outputs and draw valid conclusions from the same data set.
Ignoring negative cases
Cherry-picking quotes that confirm an existing hypothesis undermines credibility. Rigorous qualitative analysis requires actively searching for contradictory evidence. When disconfirming data is excluded, findings look cleaner than they are, and stakeholders who later encounter contradictions lose confidence in the entire research program.
Delivering findings without evidence trails
Stakeholders distrust themes they cannot trace to original conversations. Every theme should connect directly to video clips and verbatim quotes. Conveo's analysis layer maintains this link automatically, so every AI-generated finding traces back to the original session, giving stakeholders the evidence they need to act with confidence.
How Conveo transforms interview analysis from bottleneck to competitive advantage
Knowing how to analyze interview data in qualitative research is one thing. Having the infrastructure to do it consistently, at scale, without losing depth or stakeholder trust is another problem entirely. The bottlenecks covered in this article, manual coding, slow synthesis, fragmented outputs, findings that die in decks, are workflow constraints. They are not inherent to qualitative research itself. What changes when those constraints are removed is what Conveo is built around.
The workflow transformation shows up in outcomes, not feature lists. AI-moderated interviews with adaptive probing generate richer, more analyzable responses than static question guides because the AI follows what participants actually say rather than mechanically moving to the next item. AI-surfaced theme clustering and sentiment analysis surface recurring patterns across large transcript sets, with analysts reviewing and validating the output rather than building it line by line. Multimodal analysis captures voice tone, facial expressions, and on-screen objects alongside interview transcripts, so findings reflect the full conversation. Every theme ties back to a video clip and verbatim quote, making findings auditable in stakeholder reviews. Insights flow into a searchable library, so the organizational knowledge your team builds compounds across research projects over time rather than expiring with each study, serving clients who need continuous qualitative intelligence.
"The AI doesn't just summarize, it surfaces patterns I wouldn't have spotted reading transcripts."
CMI Manager, Edgard & Cooper
Conveo is SOC 2 certified, GDPR-compliant, and supports EU regional data hosting. Participants are real people in real conversations: no synthetic participants, no avatar-based qualitative data, no black-box outputs that procurement teams cannot audit.
Conveo is purpose-built for enterprise and mid-market research teams running ongoing qualitative programs and brand and innovation initiatives. It is not the right fit for one-off research projects or organizations without a dedicated research function.
Frequently Asked Questions
Can you analyze interview data in qualitative research?
How do you analyze qualitative interview data with AI?
What is the best way to analyze qualitative interview data?
Can you analyze qualitative data from international, multi-market research interviews?
What tools are used to analyze qualitative interview data?

